PolicyGradient公式推导
本文是对Sutton的《Reinforcement learning An introduction》书中第13章Policy Gradient Methods部分的总结,主要包括Policy Gradient方法的离散时间情形下的公式推导,REINFORCE算法,REINFORCE with Baseline算法,Short Corridor with switched actions环境下的仿真。
Policy Gradient
和PG算法相对应的是基于action-value的方法,这些方法学习动作的价值然后根据这些价值的大小选择行为,但是对于PG算法来说,直接学习一个参数化的策略,该策略的输入是状态,输出是动作,策略可以直接选择动作而不是依据价值函数进行判断,用
策略参数的学习需要基于某种性能度量
其中,
Policy Approximation and its Advantages
在策略梯度方法中,策略可以使用任意的方式进行参数化,只要
如果动作空间是离散的并且不是很大,可以对每一个“状态-动作”二元组估计一个参数化的价值偏好
动作偏好值
根据softmax分布选择动作的一个好处是近似策略可以接近于一个确定策略,因为动作偏好不趋向于任何特定的数值,他们趋向于最优的随机策略,如果最优策略是确定的,则最优动作的偏好值将可能趋向无限大于所有次优的动作。
另一个好处是它可以以任意的概率来选择动作。再有重要函数近似的问题中,最好的近似策略可能是一个随机策略。例如,在非完全信息的纸牌游戏中,最优的策略一般是以特定的概率选择两种不同的玩法。
策略梯度定理的证明:
从上述策略参数更新的方式来看,我们的目的就是算出
根据有限马尔科夫链的原理,可以画出下列回溯图:

从而:
根据微分的基本运算法则,可得:
根据回溯图:
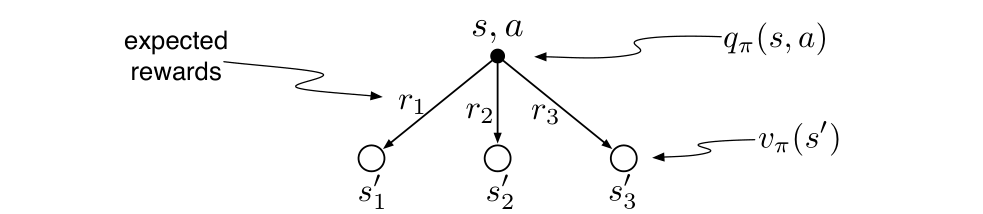
可将
又因为在
将之代入上式可得:
上述是一个递归的形式,可以将
代入上式可得:
考虑一个下面这样的状态访问序列并将从状态
对于不同的
- 当
时: 。 - 当
时,遍历在状态 下所有可能的动作 ,然后将所有从元组 转移到目标状态的概率累加: - 设目标是从状态
开始依照策略 经过 个时间步最终达到目标状态 。为了实现这个目标,可以先从状态 开始经过 个时间步后达到某个中间状态 (任何一个状态 均可成为中间状态),然后经过最后一个时间步到达目标状态 。这样的话,可以递归的计算访问概率:
根据上述所说的三种情况,可以递归的展开
因此,
REINFORCE:蒙特卡洛策略梯度
PG算法的随机梯度上升,需要一种获取样本的方法,这些采样的样本梯度的期望正比于性能指标对于策略参数的实际梯度。这些样本只需要正比于实际的梯度即可,因为任何常数的正比系数显然可以被吸收到步长参数
因此,PG算法可以写成:
其中,
继续上述的推导可得:
括号中的最后一个表达式是可以通过每步的采样计算得到的,它的期望等于真实的梯度。
又因为
最终算法的流程图:

作为一个随机梯度方法,REINFORCE有很好的理论收敛保证。每个episode的期望更新和性能指标的真实梯度的方向相同。这可以保证期望意义下的性能指标的改善,只要
但是,作为蒙特卡洛方法,REINFORCE可能有较高的方差,因此导致学习缓慢。
REINFORCE with Baseline
可以将策略梯度定理进行推广,在其中加入任意一个与动作价值函数进行对比的baseline
这个baseline可以是任意函数,甚至是一个随机变量,只要不随着动作
包含baseline的REINFORCE算法是之前REINFORCE算法的更一般的推广:
一般来说,加入这个baseline不会使更新值的期望发生变化,但是对方差有很大的影响,具体需要进一步推导一下。
具体的算法如下:

Short Corridor with switched actions环境下的仿真
环境描述
Short Corridor with switched actions是Sutton书中的一个环境:
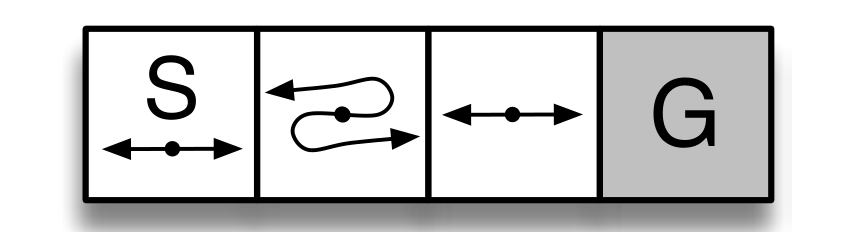
有4个状态:[0, 1, 2, 3],其中,第4个状态:G,是终止状态,在第二个状态:1,动作会反向,例如执行向左的动作,实际会向右。
每个状态下有2个动作,向左或者向右,0表示向左,1表示向右。
每一步的reward是-1。
仿真
1. 解析解
系统模型已知,可以直接求解Bellman方程,
所以该系统的Bellman方程为:
解线性方程组可得:
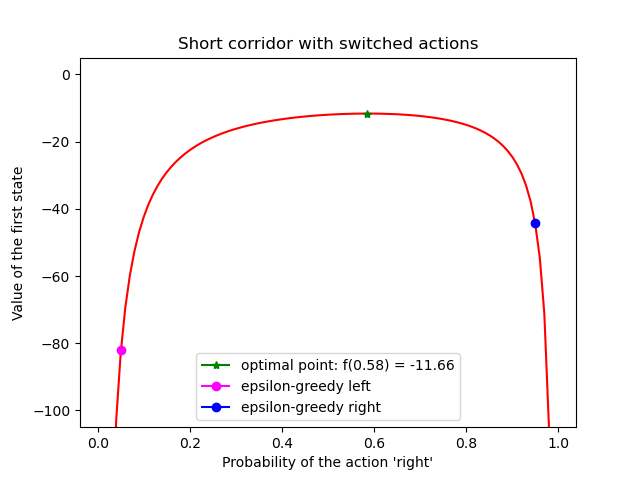
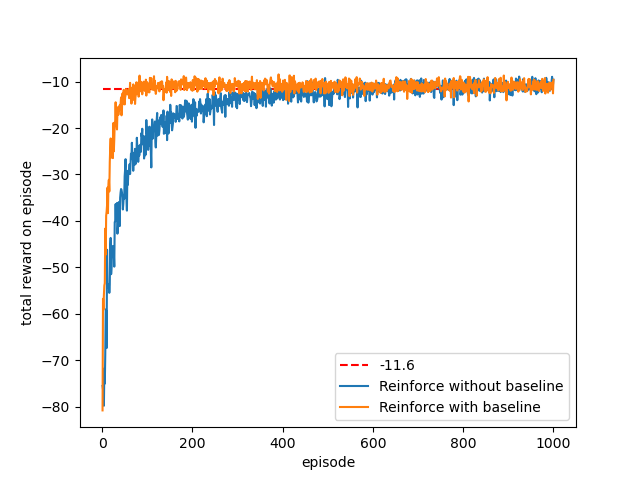
2. 假设环境模型未知(即无法写出Bellman方程)
REINFORCE with and without Baseline
openai gym maze环境下的仿真

暂时还没调试好,训练过程不收敛或者陷入局部最优,训练的过程发现初始参数的设定,学习率
- 标题: PolicyGradient公式推导
- 作者: Oliver xu
- 创建于 : 2020-08-01 10:43:54
- 更新于 : 2026-07-15 21:43:51
- 链接: https://blog.oliverxu.cn/2020/08/01/PolicyGradient公式推导/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。