最近在准备拟定自己的研究方向及资格考试答辩,然而,看了很多,发现实在太难确定方向了,旁人都建议说边做边找,做的过程中慢慢再挖掘并补充,且自己以前的确看的太多太杂了(虽然也是不得已而为之),现在已经是第二年快结束了,该定下来研究方向了,遂不再继续广泛挖掘,直接专注于某一个具体的小点进行深入研究。和实验室师兄一起解决SMPC的问题,这周先整理下MPC相关的笔记和理解。
MPC基本原理 MPC基本目标是保持在
考虑这样一个确定系统:
其中,
控制和状态的约束为:
并且我们假设系统可以被控制到初始值且以零cost的方式:
MPC的基本思想就是对于给定的初始状态
MPC具体算法流程:
Step1: 求解一个lookahead问题,需要
Step2: 对于
Step3: 在下一个时刻,MPC继续不断重复该求解过程
MPC基本理念
传统的MPC问题其实就是一个二次规划问题,首先MPC算法中有两个比较关键的参数,一个是预测时域
所以MPC方法其实很简单,毕竟这已经是从上世纪70年代就开始运用起来的控制方法了。但是其multistep lookahead的控制思想还是很有道理的,通过计算未来
优化方法及框架 由于上面所讲的已经将MPC问题转化为一个二次规划问题(可以凸,也可以非凸),所以,可以直接使用常见的优化包 来求解。
截止2021年3月20日,我大致看了下几个工具包,主要有:CVXPY(3.2K star), CVXOPT(729 star),AMP,CVXGEN等,但是这些我都没咋细看,看了其他两个,一个是OSQP(690 star),专门用来求解二次规划问题的,还有就是casadi(714 Star),一个用C++写的,并且有各种语言接口的包。
OSQP的文档中给出了一个MPC的demo,https://osqp.org/docs/examples/mpc.html
各种框架分别适用什么场景还需要以后继续探索,自己其实之前都在搞强化学习,一般都是用梯度下降 ,对于这些优化问题其实没有咋深入了解,不过基本的凸优化方法和原理还是懂一些的,有大佬看到这里的话可以教教我各框架的应用场景和易用程度及其性能分析。
简单的代码实现 对于之前的一篇文章中 所研究的控制对象进行了MPC控制的测试,其系统表示如下:
对于给定的线性系统:
其中,
初始状态
实现的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 import sysfrom cvxpy import *import numpy as np import scipy as spfrom scipy import sparseimport randomimport sympyfrom scipy.optimize import minimizeimport matplotlib.pyplot as pltimport timestart_time = time.time() A = sympy.Matrix([[0 , 0.1 ], [0.3 , -1 ]]) B = sympy.Matrix([[0. ], [0.5 ]]) [nx, nu] = B.shape Q = sympy.Matrix([[1 , 0 ], [0 , 1 ]]) R = 1.0 *sympy.eye(1 ) N = 20 P = round (0.2 * N) x0_list = [] x1_list = [] u_list = [] u = list (sympy.symbols('u:{}' .format (P))) u_last = u[-1 ] for i in range (N-P): u.append(u_last) x = [0 for i in range (N+1 )] x0 = sympy.Matrix([[1.0 ], [-1.0 ]]) xr = sympy.Matrix([[0.0 ], [0.0 ]]) x[0 ] = x0 x0_list.append(x[0 ][0 ]) x1_list.append(x[0 ][1 ]) for i in range (20 ): objective = (xr-x[0 ]).T*Q*(xr-x[0 ]) + u[0 ].transpose()*R*u[0 ] for k in range (1 , N): x[k]= A*x[k-1 ] + B*u[k-1 ] objective += (xr-x[k]).T*Q*(xr-x[k]) + u[k].transpose()*R*u[k] x[N] = A*x[N-1 ] + B*u[N-1 ] objective += (xr-x[N]).T*Q*(xr-x[N]) F = objective[0 ] J = sympy.lambdify([u[0 :P]] , F, "scipy" ) res = minimize(J, np.array([1 for i in range (P)]), method="nelder-mead" ) print ("最小值是:{}" .format (res.fun)) print ("最优解是:{}" .format (res.x)) print ("当前状态:x[0]={}" .format (x[0 ])) next_x = A*x[0 ]+B*res.x[0 ] x0_list.append(next_x[0 ]) x1_list.append(next_x[1 ]) u_list.append(res.x[0 ]) x[0 ] = next_x print (50 *'#' ) end_time = time.time() print ("N={}时,总共花费时间:{}" .format (N, end_time-start_time))plt.plot(list (range (len (x0_list))), x0_list, color='blue' , label='x0' ) plt.plot(list (range (len (x0_list))), x1_list, color='yellow' , label='x1' ) plt.plot(list (range (len (u_list))), u_list, color='red' , label='u' ) plt.legend() plt.savefig('./test.pdf' )
由于使用这个scipy中的二次规划函数,所以MPC其实很简单,其代码写的很短,如果使用上述所提到的最优化工具箱,那还可以更加简短。
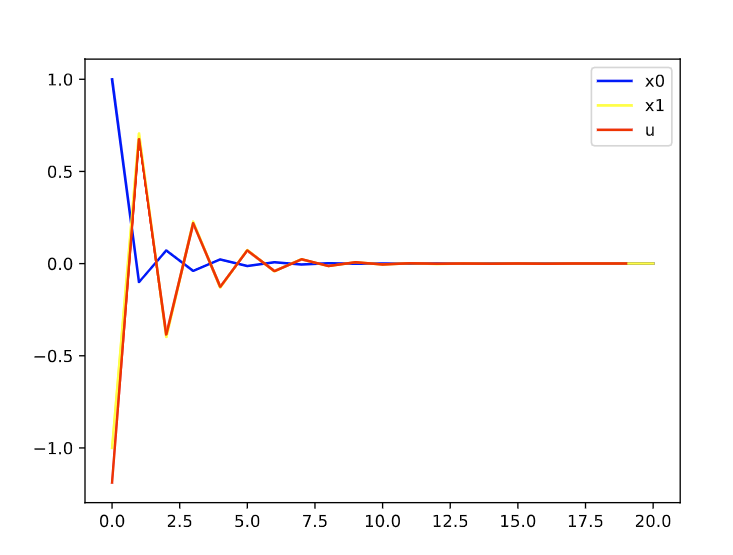
仿真验证控制时域和控制时域对控制器性能的影响 N=20, P=4时:
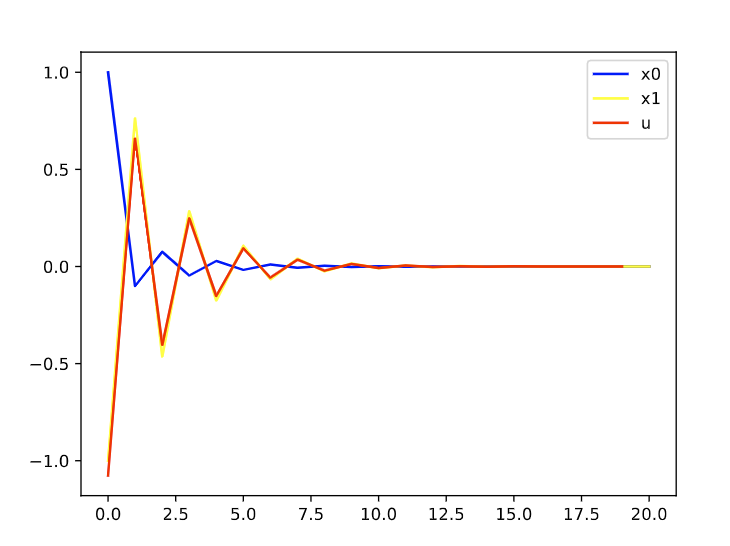
N=30,P=6
可以发现,基本上差不多。
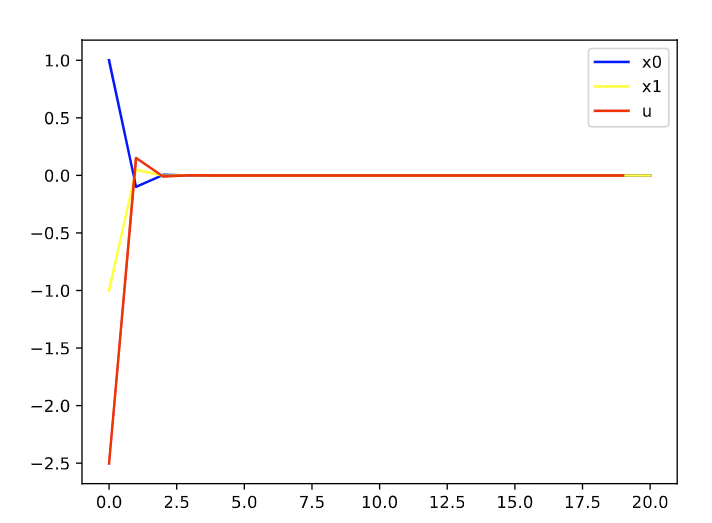
N=30,P=2
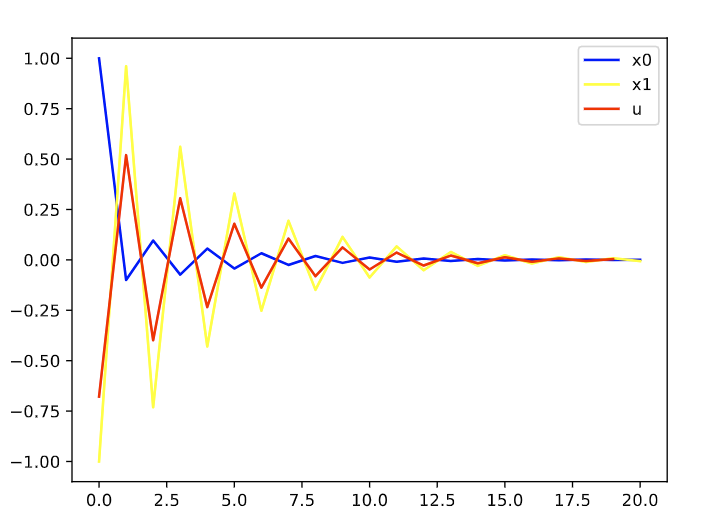
N=30,P=1
MPC算法的计算效率 因为当前MPC其实还是只能做中上层的控制调度,对于要求高的实时控制,还是很难做的,包括实时嵌入式控制等,主要原因在于其每个时刻都需要做一个最优化求解,所以MPC的求解效率很大程度上取决于最优化方法的求解效率,这篇博客用的是NM算法,一个很简单的无约束优化方法。具体效率分析待补充。
MPC与RL的关系 和强化学习相比,强化学习更多的是采用不断采样,求解期望,要么近似value function,要么近似policy function,所以,给人感觉其实RL有点笨笨的感觉,像通过各种试探,把解空间都大量搜索一遍,当时RL和DP相比,还是要聪明了不少,效率更高,毕竟是一种近似算法。