Input Convex Neural Network复现及仿真验证 《Input Convex Neural Networks》
《Optimal Control Via Neural Networks: A Convex Approach》
对于复杂系统的控制往往分为两步,对系统的辨识和控制器的设计。 深度神经网络被证明在辨识任务中取得了重大成功,但是,由于这些辨识出来的系统往往是非线性和非凸的,其控制器很难设计,所以,实际系统往往还是用线性模型去逼近,尽管这些线性模型的拟合能力很弱,因此,往往设计出来的控制器的性能都不行。
这两篇文章,主要提出了ICNN及其改进网络结构,ICNN的特点就是对于输入是凸的,第一篇文章主要提出了ICNN这一网络结构,通过将神经网络的前向通道中的权重设置为非负值,这一简单的改变,就可以将神经网络变为输入凸的,且该网络的拟合能力并为受到较大的影响。
这篇文章主要完成3点:
复现ICNN,原版的ICNN是用tensorflow写的,代码不全,且使用了较老的库版本,运行不了,在此采用pytorch进行复现出一个通用程序。 对于一个给定的函数: 对于《Input Convex Neural Networks》中的simulation中的synthetic 2D example和《Optimal Control Via Neural Networks: A Convex Approach》中的APPENDIX中的Toy Example分别进行复现及仿真验证。 ICNN原理及证明 ICNN网络结构
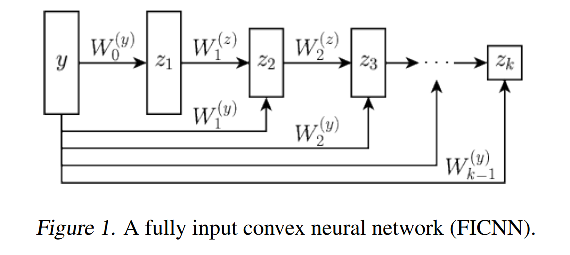
Figure1是全连接的凸的,k层ICNN,记为:FICNN,令输入记为:
结论 函数
分析:
ICNN网络结构中,从输入直接传递到隐含层的叫"passthrough",这样的连接在传统的前馈神经网络中是没有必要的,因为前面的神经网络的层的信息总是会被映射到下一个神经网络层中,但是在ICNN中,由于
对于
passthrough中的weight和bias都是可以为负的,没有限制。
ICNN输入凸的证明 定义:给定函数
定理:对于任何在某个紧集上的Lipshchitz凸的连续函数,存在一个神经网络,其权重是非负的,且激活函数使用的是Relu函数,来满足定义1中的定义。
引理:给定一个连续的Lipschitz函数
证明过程:
主要采用了两个凸优化中基本的定理:
凸函数的非负先行组合还是凸函数 凸函数和凸的非减的函数还是凸函数 证明是通过构造性的证明,我们先构建一个神经网络,使用Relu函数,其权重有正有负,然后通过构造负的输入,可以将该神经网络不同层之间的权重可以限制为非负。
证明的思路是首先证明一个凸函数可以使用一系列仿射函数的最大值表示(凸优化中的结论),然后将该最大值用神经网络的形式进行表示(这两篇文章的工作),换句话说,这两篇文章就是证明了这样的神经网络可以转换为一系列仿射函数的最大值。
证明:
首先考虑两个仿射函数的最大值:
我们的目标是将这个最大值,用神经网络来表示,将其重写为:
现在定义一个2层的神经网络:
其中,
上面的定义可以直接扩展到
将
因此任何系数矩阵和输入向量的内积都可以写成一个非负系数矩阵和扩展输入
ICNN基本结构Pytorch复现 仿真算例:
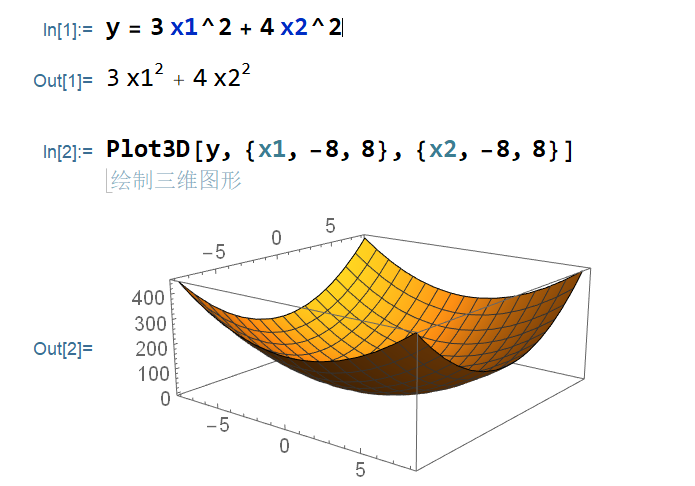
训练数据生成 1 2 3 4 5 x1 = torch.linspace(-5 , 5 , steps=300 )+torch.rand(1 ) x2 = torch.linspace(-5 , 5 , steps=300 )-torch.rand(1 ) x = [torch.tensor([np.random.choice(x1), np.random.choice(x2)]).unsqueeze(0 ) for i in range (1000 )] x = torch.cat(x, dim=0 ) y = (3 *x[:, 0 ]**2 + 4 *x[:, 1 ]**2 ).unsqueeze(1 )
在-5, 5中随机采样1000个数据点
验证方法:对单个目标进行验证时,当输入是[2, 2]时,理论输出应该是[28],同时,输出其MSE的数值并画出其图片。
对比其拟合能力: 普通神经网络的拟合能力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Model (nn.Module): ''' 定义普通全连结神经网络模型 ''' def __init__ (self, n_feature=2 , n_hidden=4 , n_output=1 , nGdIter=30 ): super (Model, self ).__init__() self .input_layer = nn.Linear(n_feature, n_hidden) self .hidden_layer = nn.Linear(n_hidden, n_hidden) self .output_layer = nn.Linear(n_hidden, n_output) self .act = nn.ReLU() def forward (self, x ): x = self .input_layer(x) x = self .act(x) x = self .hidden_layer(x) x = self .act(x) x = self .output_layer(x) return x def test_noncvx_network (): x1 = torch.linspace(-5 , 5 , steps=300 )+torch.rand(1 ) x2 = torch.linspace(-5 , 5 , steps=300 )-torch.rand(1 ) x = [torch.tensor([np.random.choice(x1), np.random.choice(x2)]).unsqueeze(0 ) for i in range (1000 )] x = torch.cat(x, dim=0 ) y = (3 *x[:, 0 ]**2 + 4 *x[:, 1 ]**2 ).unsqueeze(1 ) model = NonCvxModel(n_feature=2 , n_hidden=200 , n_output=1 ) criterion = torch.nn.MSELoss(reduction='sum' ) learning_rate = 1e-3 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) terminate_threshold = 1e-5 i = 0 while (True ): y_pred = model(x) loss = criterion(y_pred, y)/y.size()[0 ] optimizer.zero_grad() loss.backward() optimizer.step() i += 1 if i % 500 == 0 : print ("当前正在训练第{}次, 损失是{}" .format (i, loss.item())) test_model(model) if loss.item()<terminate_threshold: print ("训练满足精度要求,训练了{}次。" .format (i)) break
输出:
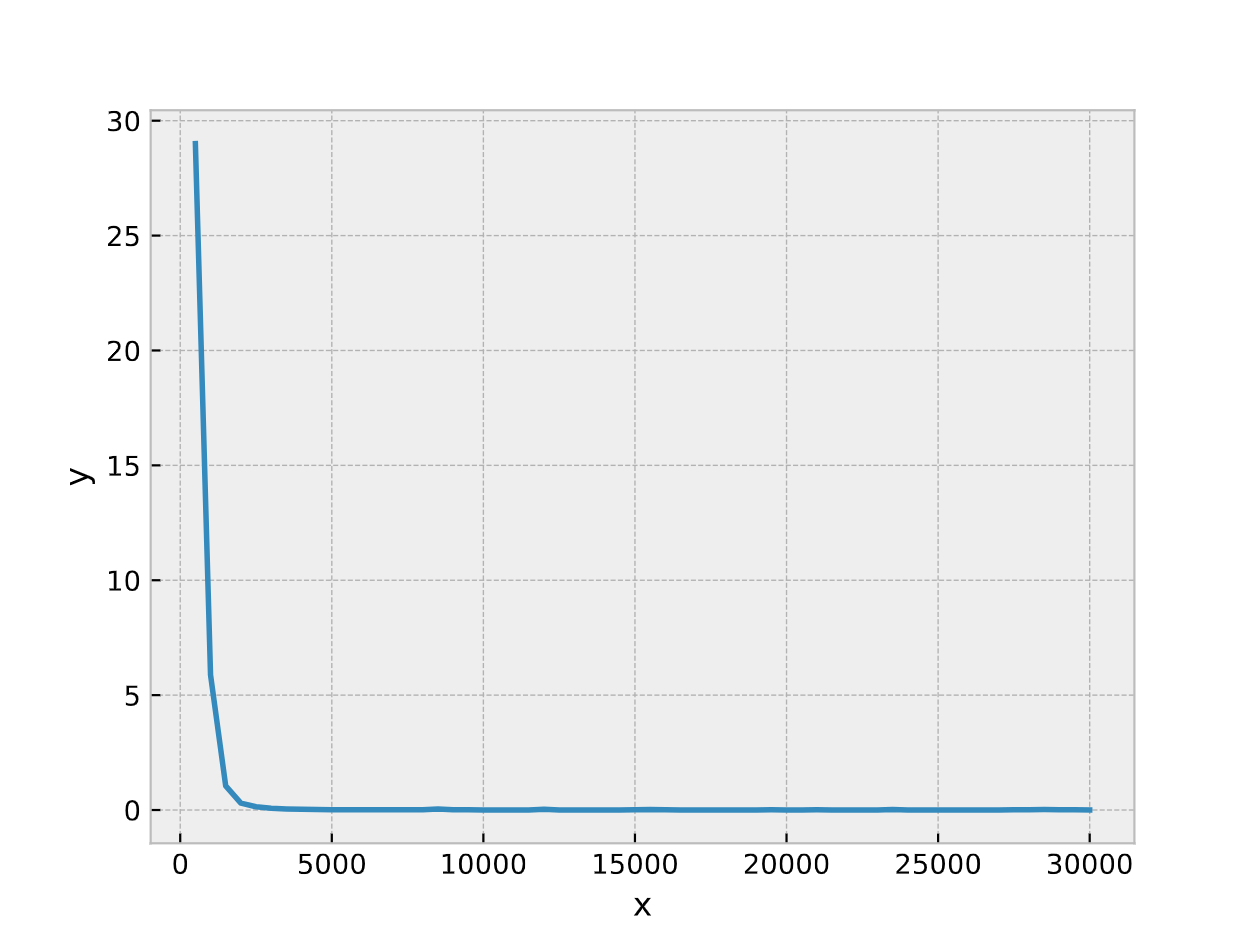
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 0 500 29.005009 1 1000 5.884062 2 1500 1.050613 3 2000 0.301482 4 2500 0.141028 5 3000 0.078763 6 3500 0.048814 7 4000 0.030913 8 4500 0.021231 9 5000 0.016060 10 5500 0.012875 11 6000 0.010986 12 6500 0.009771 13 7000 0.008564 14 7500 0.007799 15 8000 0.009830 16 8500 0.046179 17 9000 0.006437 18 9500 0.013724 19 10000 0.005822 20 10500 0.005917 21 11000 0.005384 22 11500 0.005134 23 12000 0.030397 24 12500 0.005959 25 13000 0.004671 26 13500 0.004517 27 14000 0.004421 28 14500 0.004290 29 15000 0.008322 30 15500 0.019044 31 16000 0.011500 32 16500 0.003893 33 17000 0.003794 34 17500 0.003694 35 18000 0.004458 36 18500 0.003805 37 19000 0.003468 38 19500 0.008987 39 20000 0.003343 40 20500 0.003368 41 21000 0.007225 42 21500 0.003226 43 22000 0.003124 44 22500 0.003073 45 23000 0.002998 46 23500 0.025686 47 24000 0.003000 48 24500 0.002887 49 25000 0.002838 50 25500 0.002903 51 26000 0.002845 52 26500 0.004229 53 27000 0.002733 54 27500 0.008934 55 28000 0.012964 56 28500 0.018379 57 29000 0.011293 58 29500 0.007785 59 30000 0.002500 当前正在训练第30000次, 损失是0.002500230213627219 模型预测的数值是: tensor([27.9667], grad_fn=<AddBackward0>) 实际的真实数值是: tensor([28.])
ICNN的拟合能力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class CvxModel (nn.Module): ''' 输入凸神经网络结构定义 ''' def __init__ (self, n_feature=2 , n_hidden=4 , n_output=1 , nGdIter=30 ): super (CvxModel, self ).__init__() self .input_layer = nn.Linear(n_feature, n_hidden, bias=False ) self .hidden_layer = nn.Linear(n_hidden, n_hidden, bias=False ) self .output_layer = nn.Linear(n_hidden, n_output, bias=False ) self .passthrough_layer = nn.Linear(n_feature, n_hidden) self .passthrough_output_layer = nn.Linear(n_feature, n_output) def forward (self, x ): zx1 = F.relu(self .input_layer(x)) pass1 = self .passthrough_layer(x) pass2 = self .passthrough_output_layer(x) zx2 = F.relu(self .hidden_layer(zx1) + pass1) zx3 = self .output_layer(zx2) + pass2 return zx3 class weightConstraint (): ''' 对一个特定的层的weight进行参数限制 ''' def __init__ (self ): pass def __call__ (self, module ): if hasattr (module, 'weight' ): w = module.weight.data w = w.clamp(0.0 , 100.0 ) module.weight.data = w def train_with_constrains (): x1 = torch.linspace(-5 , 5 , steps=300 )+torch.rand(1 ) x2 = torch.linspace(-5 , 5 , steps=300 )-torch.rand(1 ) x = [torch.tensor([np.random.choice(x1), np.random.choice(x2)]).unsqueeze(0 ) for i in range (1000 )] x = torch.cat(x, dim=0 ) y = (3 *x[:, 0 ]**2 + 4 *x[:, 1 ]**2 ).unsqueeze(1 ) model = CvxModel(n_feature=2 , n_hidden=200 , n_output=1 ) constraints = weightConstraint() criterion = torch.nn.MSELoss(reduction='sum' ) learning_rate = 1e-3 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) terminate_threshold = 1e-5 i = 0 while (True ): y_pred = model(x) loss = criterion(y_pred, y)/y.size()[0 ] optimizer.zero_grad() loss.backward() optimizer.step() model._modules['input_layer' ].apply(constraints) model._modules['hidden_layer' ].apply(constraints) model._modules['output_layer' ].apply(constraints) i += 1 if i % 500 == 0 : print ("当前正在训练第{}次, 损失是{}" .format (i, loss.item())) test_model(model) weight_print(model) if loss.item()<terminate_threshold: print ("训练满足精度要求,训练了{}次。" .format (i)) break
输出:
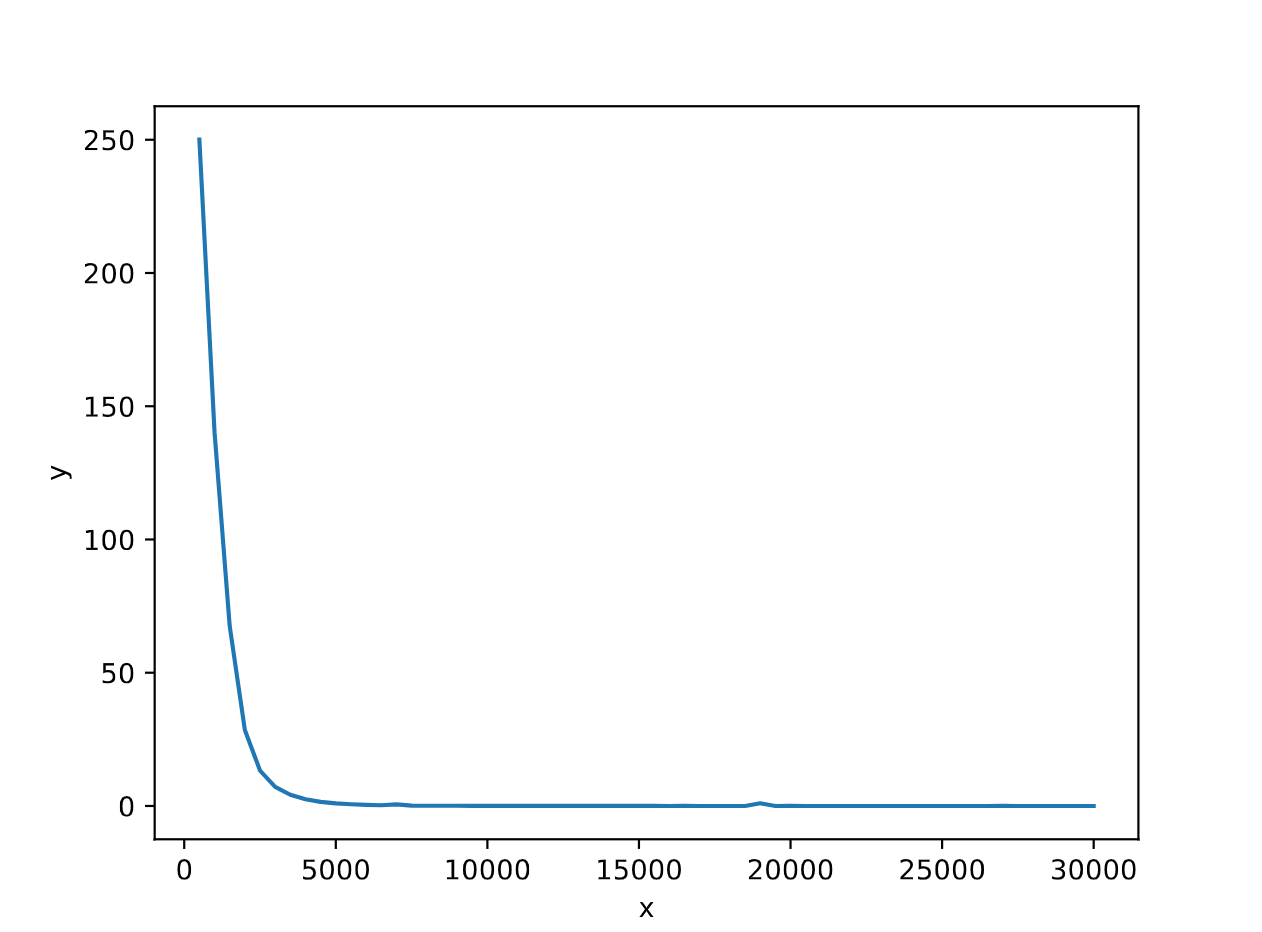
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 0 500 250.070984 1 1000 140.255447 2 1500 67.511780 3 2000 28.515696 4 2500 13.275652 5 3000 7.189941 6 3500 4.197995 7 4000 2.512518 8 4500 1.544901 9 5000 0.974513 10 5500 0.637949 11 6000 0.421706 12 6500 0.279455 13 7000 0.605793 14 7500 0.140771 15 8000 0.100952 16 8500 0.072434 17 9000 0.065805 18 9500 0.046082 19 10000 0.035448 20 10500 0.027883 21 11000 0.035439 22 11500 0.020767 23 12000 0.017025 24 12500 0.020460 25 13000 0.016357 26 13500 0.013486 27 14000 0.013836 28 14500 0.011874 29 15000 0.019069 30 15500 0.011665 31 16000 0.010154 32 16500 0.011716 33 17000 0.009304 34 17500 0.007975 35 18000 0.007628 36 18500 0.006882 37 19000 0.993199 38 19500 0.006250 39 20000 0.076224 40 20500 0.005728 41 21000 0.005862 42 21500 0.005021 43 22000 0.005911 44 22500 0.005376 45 23000 0.004734 46 23500 0.004461 47 24000 0.004778 48 24500 0.004454 49 25000 0.004859 50 25500 0.004430 51 26000 0.004365 52 26500 0.004022 53 27000 0.044836 54 27500 0.003724 55 28000 0.003986 56 28500 0.003676 57 29000 0.003535 58 29500 0.003660 59 30000 0.003258 当前正在训练第30000次, 损失是0.00325777824036777 模型预测的数值是: tensor([28.0241], grad_fn=<AddBackward0>) 实际的真实数值是: tensor([28.])
可以看出,在使用相同adam优化器参数的条件下,DNN相比ICNN,优化的速度更快。
而当将adam优化器的参数从
1 2 3 4 5 当前正在训练第500次, 损失是4.0928754806518555 模型预测的数值是: tensor([26.7256], grad_fn=<AddBackward0>) 实际的真实数值是: tensor([28.])
对于上面所仿真的普通的DNN,若将其adam优化器同时改变之后,仿真结果如下:
1 2 3 4 5 当前正在训练第500次, 损失是0.12059637159109116 模型预测的数值是: tensor([28.0837], grad_fn=<AddBackward0>) 实际的真实数值是: tensor([28.])
Adam优化器的参数对于网络的训练有着很大的影响,经过实验仿真可得:传统的DNN和ICNN都能找到一组Adam优化器参数,使得其训练效果较好。
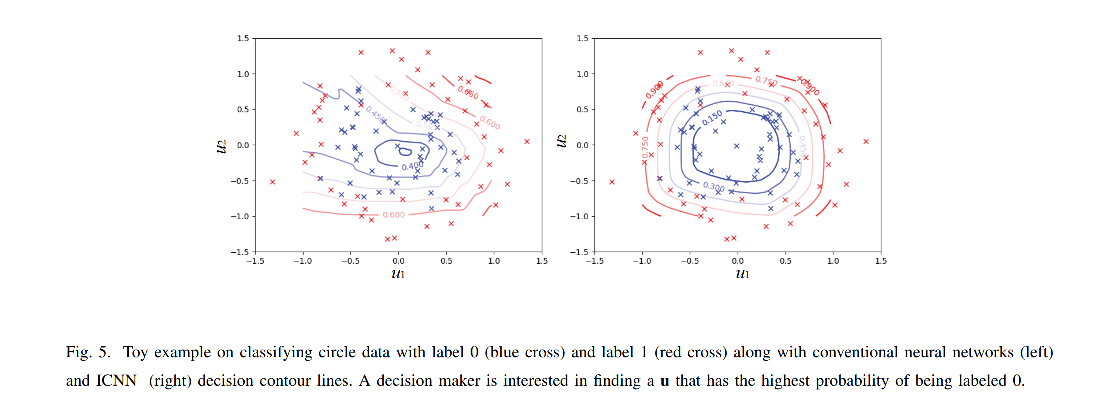
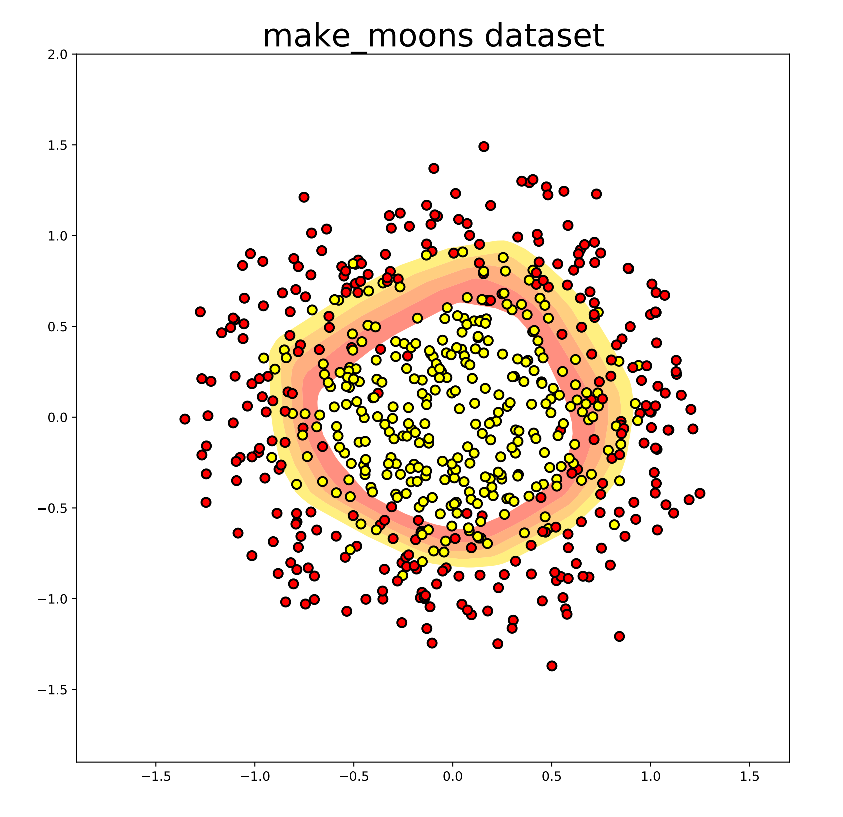
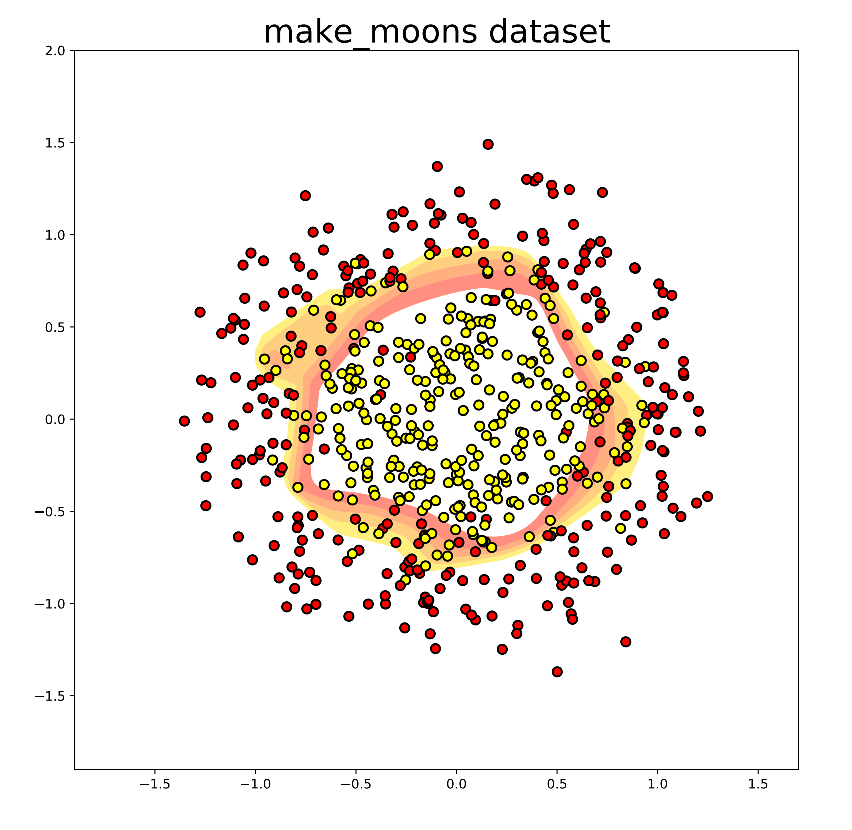
原始论文中的仿真验证的复现 第二篇论文中给出了一个二分类问题的仿真,二维输入变量,每一个维度的范围是
上图显示了普通NN和ICNN的决策边界,网络包含两层隐藏层,每一层有200个神经元,左边的图显示出了传统的神经网络,会有许多的之字形的的边界,也就是意味着决策是非凸的,所以优化的时候会存在许多局部最优值,而右边的图显示了ICNN的决策边界,可以看出,优化决策是一个凸优化问题,可以找到全局最优解。
由于原始论文中未给出原始的代码,所以本文使用PyTorch进行了复现仿真对比。
第一幅图是使用ICNN进行的仿真所画的等高线,等高线的数值从内到外分别是
第二幅图是使用NN进行的仿真所画出的等高线,等高线的数值从内到外分别是
未来展望 ICNN是一种2016年提出来的新型的神经网络结构,用于解决传统的神经网络难以inference的问题,同时,经过仿真验证,ICNN的拟合能力损失不大。不过经过检索,使用ICNN结构的发表在期刊上只有几篇文章,有很多篇都是发表在了会议上(ICML),主要都是将ICML结合到特定的应用场景中。
《Data-Driven Solution for Optimal Pumping Units Scheduling of Smart Water Conservancy, 2020》这篇文章中作者在最后的展望中提到了”Additional effort is also needed to develop data-driven or learning-based models with convex characteristics of input–output dynamic relation, e.g., the input convex neural network that is able to model the convex optimization problem and obtain the optimal control solutions.“