PPO算法公式推导
论文:
[1] Schulman, J., Levine, S., Moritz, P., Jordan, M. I. & Abbeel, P. Trust Region Policy Optimization. arXiv:1502.05477 [cs] (2017).
[2] Schulman, J., Wolski, F., Dhariwal, P., Radford, A. & Klimov, O. Proximal Policy Optimization Algorithms. arXiv:1707.06347 [cs] (2017).
[3] Heess, N. et al. Emergence of Locomotion Behaviours in Rich Environments. arXiv:1707.02286 [cs] (2017).
第一、二篇是openai的,第三篇是deepmind的
Trust Region Policy Optimization算法是在2015年由UCB/Openai的John Schulman提出的,基本思想就是在传统的Policy Gradient算法中对梯度的更新增加一个信赖域,来保证梯度更新前后的策略相差不超过一定的阈值,用两个概率分布的KL散度来衡量这个阈值,TRPO算法的表达形式中有一个硬约束,这给求解最优问题带来了困难,而PPO则是在2017年由UCB/Openai的John Schulman提出的,是TRPO的近似算法,将TRPO的软约束转化成目标函数中的一个惩罚项,以此来简化计算,方便实现。
TRPO算法推导
Notation
令
其中,
state-action值函数的定义:
价值函数的定义:
优势函数:
Lemma1:策略差分定理:原始策略记为
上述等式能够体现TRPO的思想:将新的策略得到的性能函数写成旧策略的性能函数加上一个新策略对旧策略的的优势函数的期望值,若能保证这个期望值是正数,则可以保证新策略的性能函数要优于旧策略的性能函数。
这个定理由2002年 Kakade & Langford证得:
因为
定义discounted visitation frequencies:
定义这个频率的目的主要是换一个角度来表示基于累计折扣回报函数的性能函数,因为
当
当
通过使用discounted visitation frequencies方法,可以将上述级数形式的期望写成如下容易处理的形式
因为
其中,
对于任意的参数
因此,当对策略进行一步充分小的更新,
上述过程只说明了一个充分的改进会得到非减的性能指标序列,但是选取步长很重要,选的小了会导致收敛速度慢,选了大了会导致可能的不能得到非减的性能指标序列,因此,(Kakade & Langford)提出了一个policy update的方法:conservative policy iteration(保守策略迭代),该方法给出了一个显式策略更新的下界:
令
(Kakade & Langford)推导出来的期望折扣累计回报的下界是:
以上都是(Kakade & Langford 2002)的结论和证明
其中
用概率论中的全变差距离来衡量两个策略之间的差距,
其中,
因为全变差距离和KL散度具有关系:
所以可以将
利用KL divergence来衡量差距,计算方法:
对于离散分布:
对于连续分布:
TRPO算法

策略的单调改进:TRPO算法能够保证策略每次更新都是单调改进的,即值函数
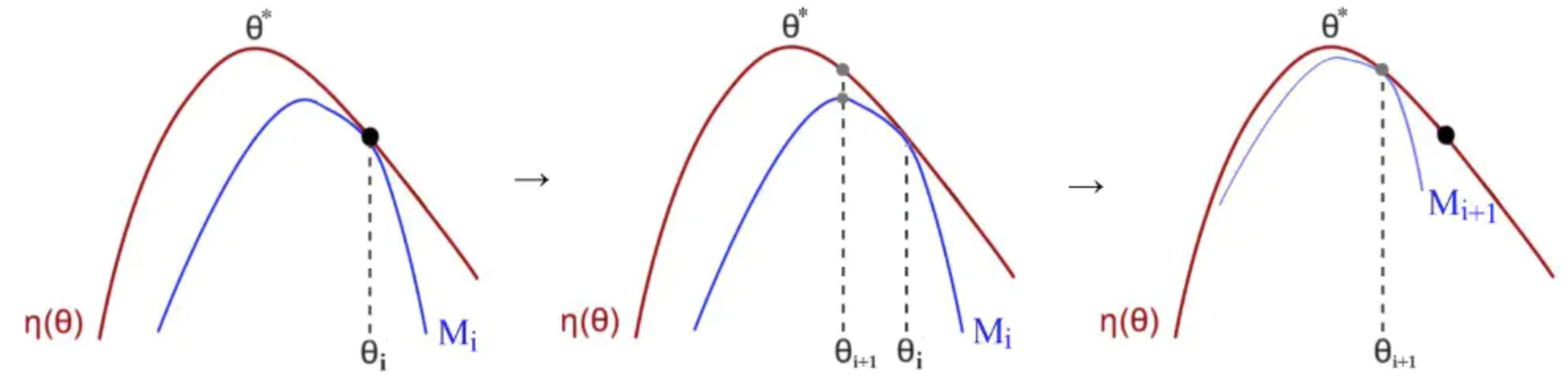
PPO算法
TRPO算法是找到原目标函数的替代函数,并最大化这个替代函数,优化问题的约束是策略参数的更新不能超过一个设定的阈值,优化过程可以写成:
PPO是TRPO的一个改进,或者可以说是一个近似算法,可以将上述的带约束优化问题转化为无约束优化问题,可以写出TRPO的另一个形式:
令
TRPO最大化一个替代的目标函数:
如果使用策略迭代进行求解,那么策略的更新的步长可能会很大,以下是PPO的一个实现:对ration直接进行限制
上述min中有两项:第一项为
Clip:为目标函数限定一个范围,意思就是通过计算概率比
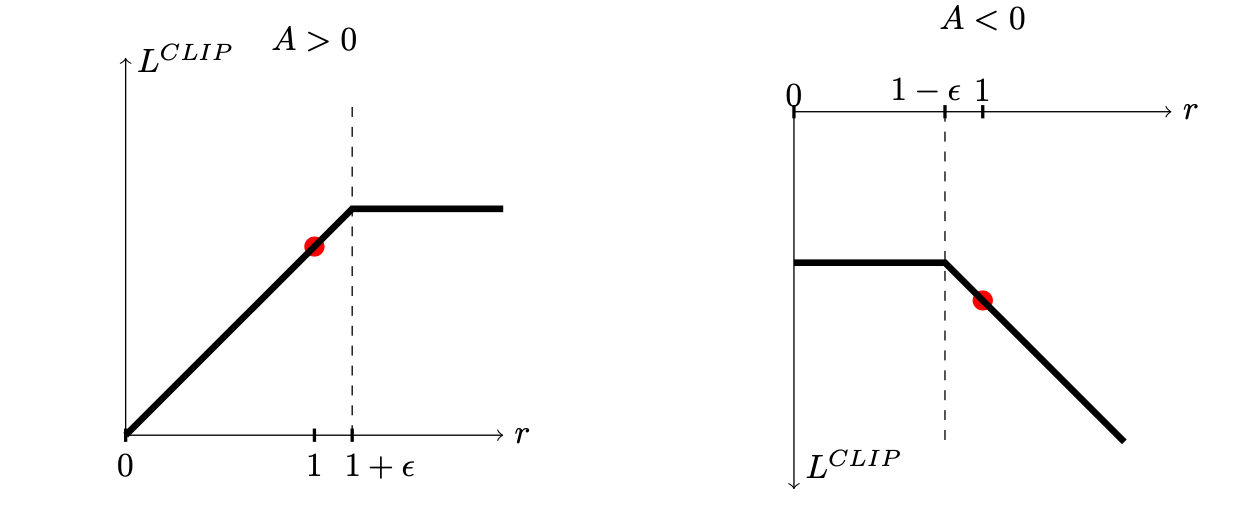
PPO算法的第二种形式:
以目标函数加入惩罚项的形式:
其中,
计算两个策略的KL散度:
- 标题: PPO算法公式推导
- 作者: Oliver xu
- 创建于 : 2020-09-07 11:46:02
- 更新于 : 2026-07-15 21:43:51
- 链接: https://blog.oliverxu.cn/2020/09/07/PPO算法公式推导/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。